
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- From Machine Reading Comprehension to Dialogue State Tracking: Bridging the Gap
- 검색엔진
- Leveraging Slot Descriptions for Zero-Shot Cross-Domain Dialogue State Tracking
- 정보처리기사전공자
- 모두의딥러닝
- 정보처리기사전공자합격후기
- nlp논문리뷰
- 백준
- MySQL
- Zero-shot transfer learning with synthesized data for multi-domain dialogue state tracking
- SUMBT:Slot-Utterance Matching for Universal and Scalable Belief Tracking
- Python
- few shot dst
- 자연어처리 논문 리뷰
- How Much Knowledge Can You Pack Into the Parameters of a Language Model?
- til
- 파이썬을 파이썬답게
- Few Shot Dialogue State Tracking using Meta-learning
- 딥러닝기초
- 다이나믹 프로그래밍
- dialogue state tracking
- 데이터 합성
- DST zeroshot learning
- 2020정보처리기사필기
- 정보처리기사 수제비
- 정보처리기사 책 추천
- 프로그래머스
- DST fewshot learning
- fasttext text classification 한글
- classification text
Archives
- Today
- Total
🌲자라나는청년
딥러닝 기초 2일차 본문
반응형
CNN
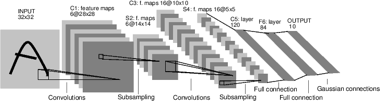
Before CNN
- 그림이 조금만 달라져도 컴퓨터는 다른 것이라고 인식
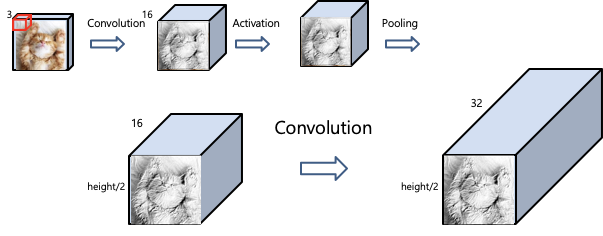
Convolution
- fiter를 만들어서 넣는것(padding도 넣어준다)
- filter가 여러개 -> 여러개가 생기게 된다.
- filter모양과 실제 그림과 같을 때 가장 큰 값이 나온다.(->특징)
- filter = 특징을 찾는 도구!
Activation function
- convolution 된 값을 activation function을 적용한다. 주로 ReLU사용
- 장점 : 학습이 잘됨, 일반화를 잘함
Pooling
- 2x2 grid = 2x2 matrix, stride = 몇칸씩 뛰어 넘기면서 pooling을 할 것인가.
- 연산의 처리와, 일반화를 위해 정보를 줄이는 과정
Basic Architecture
- convolution -> activate -> pooling
- 차원이 높아지는 이유 : convolution filter가 한개가 아님!
- 마지막 단계 : 1차원으로 배열을 변경시킴 -> 마지막 노드로
- 학습방법
- one-hot vector로 정답값을 줌. (0,0,0000..0,1)
- 마지막노드의 값을 softmax를 이용해서 확률값으로 변경
- 둘을 이용해서 loss 구함(cross entropy 이용)
MNIST 를 CNN 으로 해본 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
|
#from google.colab import drive
#drive.mount('/content/drive')
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.nn.init as init
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.autograd import Variable
seed = 1
no_cuda = False
use_cuda = not no_cuda and torch.cuda.is_available()
torch.manual_seed(seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
batch_size = 16
learning_rate = 0.01
num_epoch = 10
mnist_train = dset.MNIST("./", train=True, transform=transforms.ToTensor(), target_transform=None, download=True)
mnist_test = dset.MNIST("./", train=False, transform=transforms.ToTensor(), target_transform=None, download=True)
print(mnist_train.__getitem__(0), mnist_train.__len__())
mnist_test.__getitem__(0), mnist_test.__len__()
train_loader = torch.utils.data.DataLoader(mnist_train,batch_size=batch_size, shuffle=True,num_workers=2,drop_last=True)
test_loader = torch.utils.data.DataLoader(mnist_test,batch_size=batch_size, shuffle=False,num_workers=2,drop_last=True)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# conv2d parameter
# # of input image channel, output chanel(# of filter), kernel_size(5x5 filter), stride(jump!)
self.conv1 = nn.Conv2d(1, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
# nn.Linear : 1차원의 배열로 만든다.
self.fc1 = nn.Linear(4*4*50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
return out
model = CNN().to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for i in range(num_epoch):
for j,[image,label] in enumerate(train_loader):
x = Variable(image).to(device)
y_= Variable(label).to(device)
optimizer.zero_grad()
output = model.forward(x)
loss = loss_func(output,y_)
loss.backward()
optimizer.step()
if j % 1000 == 0:
print(loss)
correct = 0
total = 0
for image,label in test_loader:
x = Variable(image,volatile=True).to(device)
y_= Variable(label).to(device)
output = model.forward(x)
_,output_index = torch.max(output,1)
total += label.size(0)
correct += (output_index == y_).sum().float()
print("Accuracy of Test Data: {}".format(100*correct/total))
###########################################################
!rm ./mnist_pretrained.pth
torch.save(model, './mnist_pretrained.pth')
|
cs |
CIFAR 를 CNN 으로 해본 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
#from google.colab import drive
#drive.mount('/content/drive')
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.nn.init as init
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.autograd import Variable
seed = 1
no_cuda = False
use_cuda = not no_cuda and torch.cuda.is_available()
torch.manual_seed(seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
mnist_train = dset.CIFAR10("./", train=True, transform=transforms.ToTensor(), target_transform=None, download=True)
mnist_test = dset.CIFAR10("./", train=False, transform=transforms.ToTensor(), target_transform=None, download=True)
print(mnist_train.__getitem__(0)[0].size(), mnist_train.__len__())
mnist_test.__getitem__(0)[0].size(), mnist_test.__len__()
train_loader = torch.utils.data.DataLoader(mnist_train,batch_size=batch_size, shuffle=True,num_workers=2,drop_last=True)
test_loader = torch.utils.data.DataLoader(mnist_test,batch_size=batch_size, shuffle=False,num_workers=2,drop_last=True)
batch_size = 16
learning_rate = 0.01
num_epoch = 100
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# conv2d parameter
# # of input image channel, output chanel(# of filter), kernel_size(5x5 filter), stride(jump!)
self.conv1 = nn.Conv2d(3, 20, 5, 1)
self.conv2 = nn.Conv2d(20, 50, 5, 1)
# nn.Linear : 1차원의 배열로 만든다.
self.fc1 = nn.Linear(5*5*50, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = x.view(-1, 5*5*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
return out
model = CNN().to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for i in range(num_epoch):
for j,[image,label] in enumerate(train_loader):
x = Variable(image).to(device)
y_= Variable(label).to(device)
optimizer.zero_grad()
output = model.forward(x)
loss = loss_func(output,y_)
loss.backward()
optimizer.step()
if j % 1000 == 0:
print(loss)
correct = 0
total = 0
for image,label in test_loader:
x = Variable(image,volatile=True).to(device)
y_= Variable(label).to(device)
output = model.forward(x)
_,output_index = torch.max(output,1)
total += label.size(0)
correct += (output_index == y_).sum().float()
print("Accuracy of Test Data: {}".format(100*correct/total))
###########################################################
!rm ./mnist_pretrained.pth
torch.save(model, './mnist_pretrained.pth')
|
cs |
내 이미지 넣어서 테스트 해보기
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
###########################################################
#import torch
#from google.colab import drive
#drive.mount('/content/drive')
load_model = torch.load('./cifar_pretrained.pth')
#load_model.to(device)
###########################################################
seed = 1
log_interval = 200
#no_cuda = False
#use_cuda = not no_cuda and torch.cuda.is_available()
#torch.manual_seed(seed)
#device = torch.device("cuda" if use_cuda else "cpu")
#kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
from skimage import io
class customdataset(torch.utils.data.Dataset):
def __init__(self, transform=None):
self.transform = transform
def __len__(self):
return 1
def __getitem__(self, idx):
img_name = './cifar_data/test_{}.jpg'.format(idx)
image = io.imread(img_name)
if self.transform is not None:
image = self.transform(image)
return image
my_set = customdataset(transform=transforms.Compose([
#transforms.CenterCrop(28),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
my_dataloader = torch.utils.data.DataLoader(my_set, batch_size=1, **kwargs)
def my_test(log_interval, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for i, data in enumerate(test_loader):
data = data.to(device)
output = model(data)
pred = output.argmax(dim=1, keepdim=True)
print('test_{} is : '.format(i) + str(pred.item()))
my_test(log_interval, load_model, device, my_dataloader)
|
cs |
반응형
'파이토치' 카테고리의 다른 글
| 모두의 딥러닝 -파이토치 ch7 정리 (0) | 2019.03.20 |
|---|---|
| 모두의 딥러닝 -파이토치 ch5-ch6 정리 (0) | 2019.03.19 |
| 모두의 딥러닝 -파이토치 ch3-ch4 정리 (0) | 2019.03.19 |
| 모두의 딥러닝 -파이토치 ch1-ch2 정리 (0) | 2019.03.19 |
'파이토치' Related Articles
more



