
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- DST zeroshot learning
- Leveraging Slot Descriptions for Zero-Shot Cross-Domain Dialogue State Tracking
- Few Shot Dialogue State Tracking using Meta-learning
- 자연어처리 논문 리뷰
- 정보처리기사 책 추천
- 정보처리기사전공자
- 데이터 합성
- DST fewshot learning
- How Much Knowledge Can You Pack Into the Parameters of a Language Model?
- 프로그래머스
- Zero-shot transfer learning with synthesized data for multi-domain dialogue state tracking
- SUMBT:Slot-Utterance Matching for Universal and Scalable Belief Tracking
- 정보처리기사 수제비
- 검색엔진
- Python
- dialogue state tracking
- 정보처리기사전공자합격후기
- MySQL
- 다이나믹 프로그래밍
- classification text
- 2020정보처리기사필기
- 모두의딥러닝
- til
- few shot dst
- 딥러닝기초
- nlp논문리뷰
- 파이썬을 파이썬답게
- 백준
- fasttext text classification 한글
- From Machine Reading Comprehension to Dialogue State Tracking: Bridging the Gap
- Today
- Total
🌲자라나는청년
[NLP논문 리뷰] Zero-shot transfer learning with synthesized data for multi-domain dialogue state tracking(2020) 본문
[NLP논문 리뷰] Zero-shot transfer learning with synthesized data for multi-domain dialogue state tracking(2020)
JihyunLee 2021. 9. 2. 00:02제목 : Zero-shot transfer learning with synthesized data for multi-domain dialogue state tracking
저자 : Giovanni Campagna Agata Foryciarz Mehrad Moradshahi Monica S. Lam
발행년도 : 2020
paper : https://arxiv.org/pdf/2005.00891.pdf
code : https://github.com/stanford-oval/genie-toolkit
Review
이번 논문은 Domain State Tracking(DST) 에서의 Zero/Few shot learning과 관련한 논문이다. 이 논문은 새로운 모델 구조를 만든것이 아니라, ontology를 이용해 대화 데이터를 "합성" 한 뒤, 합성된 데이터로만 기존에 존재하던 모델을 학습시킨 연구이다.
연구자들은 MultiOZ dataset의 구조를 보고(논문에서도 emperical 이라는 단어를 씀) 경험적으로 대화 데이터에 "패턴" 이 있다고 생각하여 MultiOZ 에서 제공하는 ontology 를 이용해서 대화데이터를 Rule based로 (논문에서는 few human-hours라고 표현) 만든 뒤 이를 baseline모델에 학습시킨 연구이다.
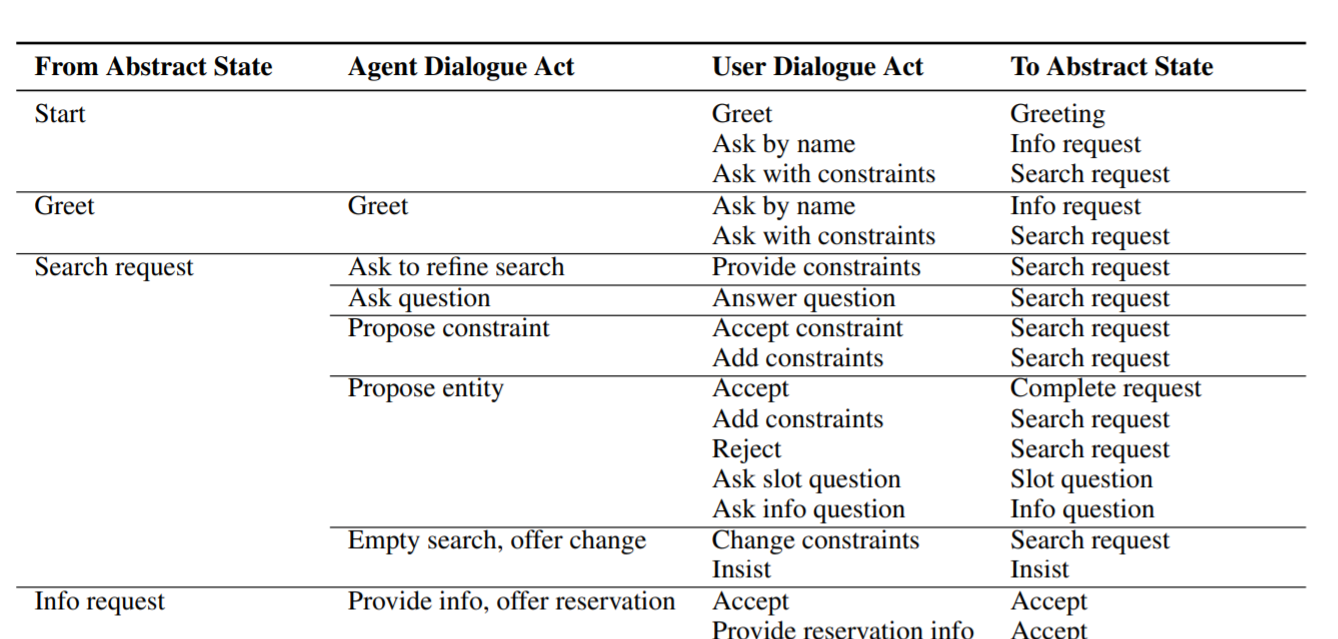
합성된 데이터로 학습시킨 모델들은 TRADE와 SUMBT이며 TRADE는 pre-trainned language model(bert와 같은..) 을 사용하지 않고, 학습과정에서 보지 않은 value를 생성할수 있다는 특징이 있는 반면 SUMBT는 Bert 를 사용하였고, 학습과정에서 보지 않은 value는 답으로 제시할수 없다는 특징이 있다.

합성된 데이터로 모델을 학습시켰을 때 결과는 원래의 결과와 크게 다르지 않다. 하지만 Zero shot 방식(목적으로 하는 domain을 제외하고 학습시킨뒤, test는 목적으로 하는 domain으로 하는 방법)으로 모델을 테스트 했을 때는 TRADE가 1/2, SUMBT가 2/3 정도의 성능을 보였다.

이를 보았을 때, pre trainned모델을 사용하는 SUMBT가 합성 데이터와의 합(?) 이 더 잘맞다고 할 수 있다.
Limitation + 내생각
앞에서 리뷰한 논문들과는 다르게 본 논문은 모델을 새로 구성하기 보단, 데이터를 학습하여 모델에 적용한 방식을 사용하였다. 이 방법이 가지고 있는 단점은
- 사람이 대화 규칙을 만들어야한다. 대화규칙을 잘 만들더라도 만들어진 대화규칙이 모든 Multi OZ가 아닌 다른 데이터에도 적용이 될 수 있을지? 의문이 들었다.
그리고 이 논문을 읽으면서 어쩌면 노가다(?) 라고 생각 할 수 있는 작업을 정교하게 했을 때, 결과가 좋다면(사실 그닥 좋은진 모르겠음..!) 정교하고 논리적으로 노가다를 진행했다면 좋은 논문으로 나올 수 있구나 하는 생각을 했다!💛



